Free-text search
Free-text search is a technique for searching a single document or a collection in a free-text database. In a free-text search, a search engine examines all of the words in every stored document as it tries to match search criteria.
Free-text search is enabled in Casewhere by default. There are also advanced settings so you can enrich and customize your search data easily.
Configuration
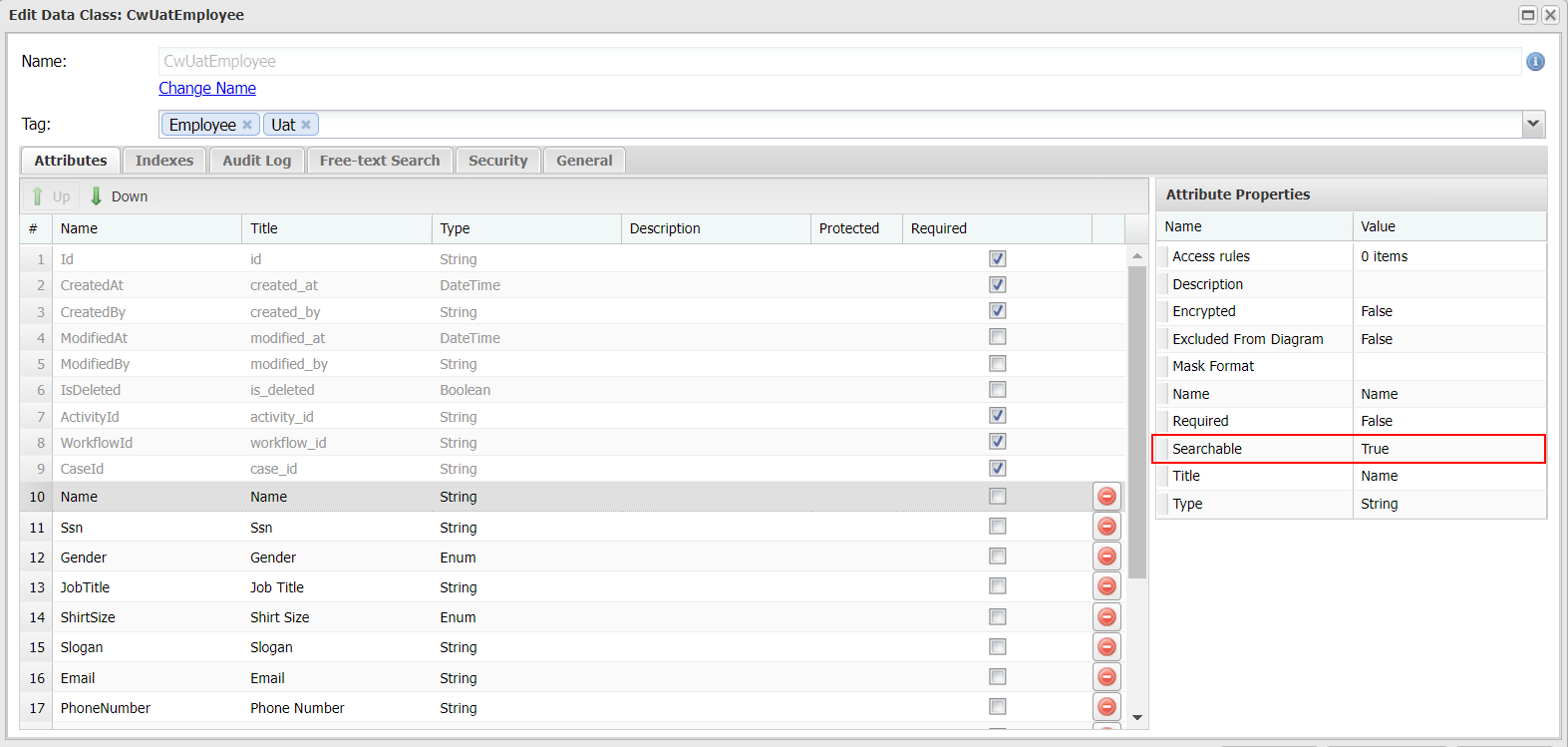
By default, Casewhere enables free-text search for all string attributes. You can disable it for a specific string field by setting Searchable to False. Other searchable types — Integer, Long, Decimal, Double, Enum, and Object — are not searchable by default; include them by setting their Searchable property to True.
Advanced settings
In the data class editor, navigate to Free-text search tab. Here you can find all advanced settings to customize your search strategy.
Wildcard index
Enable Wildcard Index to index every text field of the data class with a single index. With a wildcard index, Casewhere does not need to rebuild the text index when you add or change searchable attributes, which is convenient for evolving data models.
Data enriching
Data enriching is the process of extending your already existing data objects by providing supplementary searchable information. The additional data can be retrieved from related data objects.
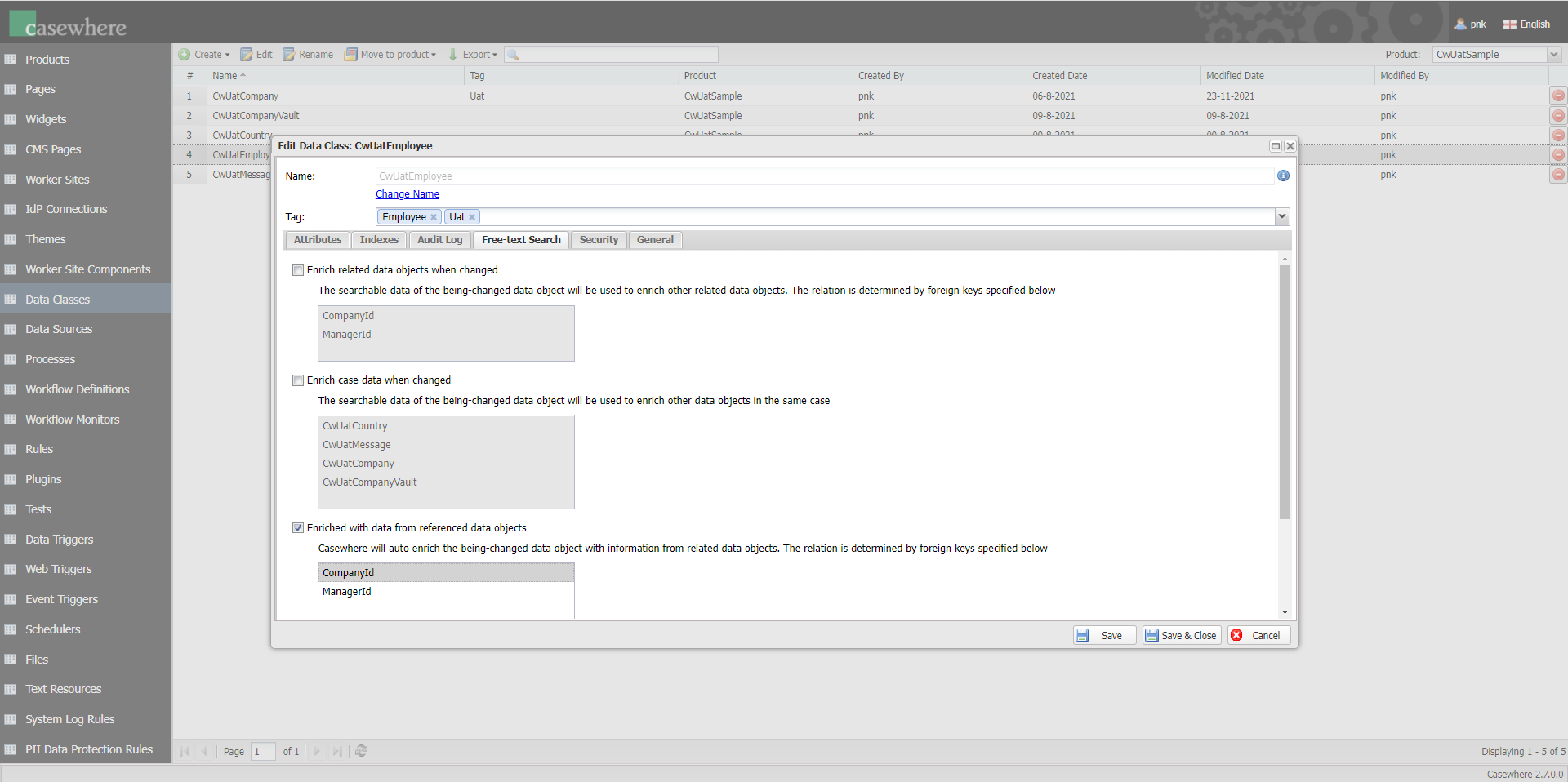
Enrich related data objects when changed
The searchable data of the being-changed data object will be used to enrich other related data objects. The relations are determined by foreign keys.
Example: The relation between Employee and Company data objects is defined by the foreign key Employee.CompanyId. By enabling this setting on Employee, every time the data object is changed, the related Company will be enriched with the employee's information.
Enrich case data when changed
The searchable data of the being-changed data object will be used to enrich other data objects in the same case.
Example: By enabling this setting on Employee, every time the data object is changed, the data objects in the same case, e.g. Contract, Email, etc., will be updated.
Enriched with data from referenced data objects
The being-changed data object will be enriched with the information from related data objects. The relation is determined by foreign keys.
Example: The relation between Employee and Company data objects is defined by the foreign key Employee.CompanyId. By enabling this setting on Employee, every time the Company data object is changed, the Employee data object in context will be enriched with the company's information.
Tokenizer
Note: Available since Casewhere 2.6.10
The built-in search engine in MongoDB performs text searches in a collection, it tokenizes the search string using whitespace and most punctuation as delimiters. You can search documents with individual words in the given text but not with partial words. To solve this problem, Casewhere implements the N-gram tokenizer to break a text down into words. Each word based on a continuous sequence of characters of the specified length. It is useful for querying languages that don’t use spaces or that have long compound words, like German.
To enable N-gram tokenizer:
- Go to Tokenizer section and check on Enable n-gram tokenizer.
- Set Min-gram and Max-gram value.
Example:
Text = "Quick Fox"
Min-gram = 1
Max-gram = 2
Output = [ "Q", "Qu", "u", "ui", "i", "ic", "c", "ck", "k", "k ", " ", " F", "F", "Fo", "o", "ox", "x" ]